Run when Platform
The platform helps your team import and build Skills that are guaranteed by design to be Safe-For-Production.
You can wrap those Skills in token-optimized Agents running on the platform, or use them with other Agentic systems.

Import Agent Skills
Out of the box, get thousands of Safe-For-Production Skills from our experts.
Build Agent Skills
Use the platform or the MCP server as a dedicated code review and CI/CD pipeline specifically designed for Safe-For-Production Skills
Run Agents
Token optimized background and foreground Agents for a wide range of SRE, DevOps, FinOps, DevEx and Platform Engineering teams
Safe-For-Production Skills included on day 1
With a Kubernetes or cloud credential, our set-up tools build thousands of safe-for-production Skills tailored for your applications, open source, infrastructure and toolchain... ready on day 1.
Add a Skill to an Agent. Grant acess to your team. You are up and running.

Build Safe-For-Production Agent Skills
Our Skill Building harness ensures that new skills built by your team follow our safe-for-production design pattern. They can be used with all major Agent platforms, and are optimized for lower token usage and extra safety with RunWhen Agents.
Our Skill Building harness is an AI-forward CI/CD pipeline built specifically for Safe-For-Production Skills.
Use it as an MCP server with all of the major AI Coding platforms if you have a dev environment set up already, or use the built in Skill Building tool in the UI.
Skills built with the RunWhen Skill Building Harness go through multiple levels of AI code review before an Agent can pick them up to ensure safety.

Run Safe-For-Production Agents
Agents run both in the background and in the foreground
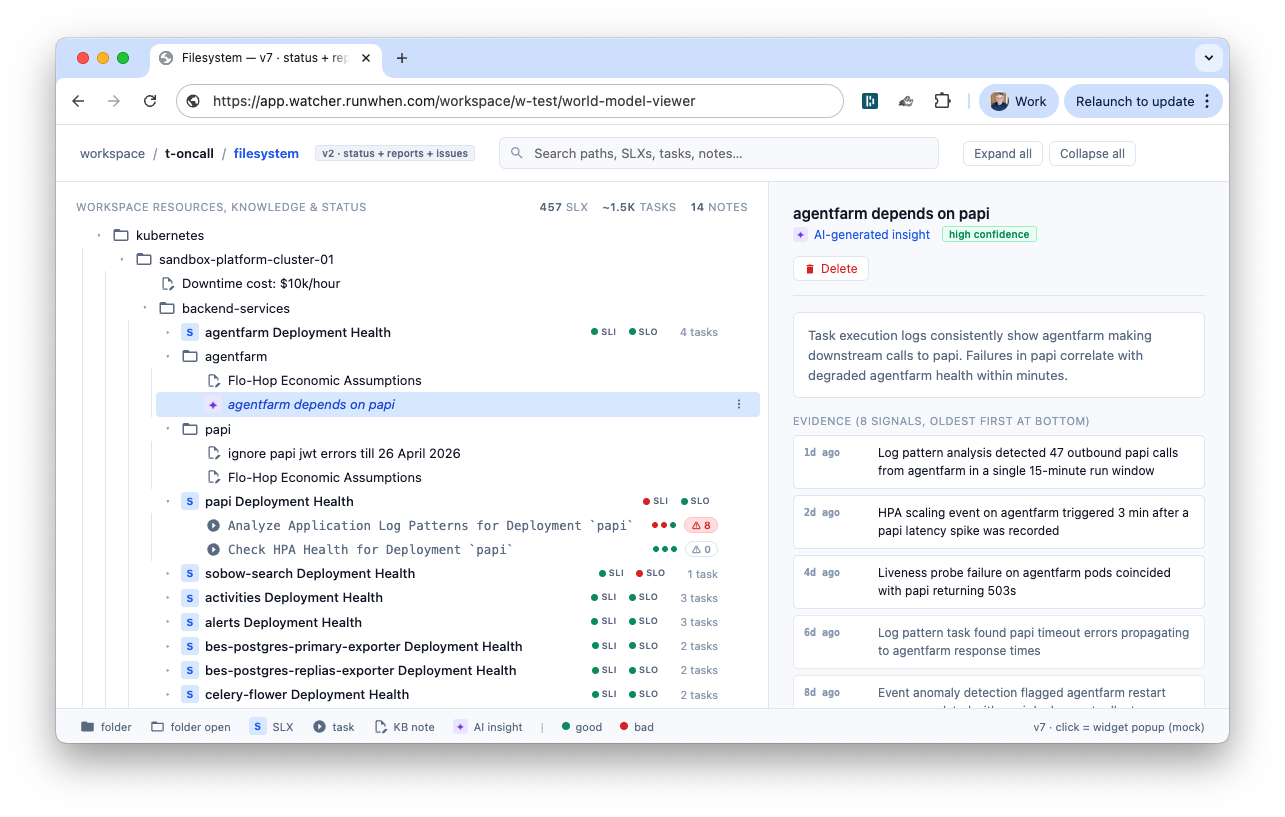
In the background, Agents are building up their own world model of your production environment. Dependencies, baselines, important events, correlations, real time health data.
In the foreground, Agents suggest Skills to run or answer questions based on the world model that has been building in the background.


High Availability and Reliability
For RunWhen Hosted and Hybrid deployments, RunWhen is focused on providing a highly available and reliable platform. For self-hosted, we provide optional professional services (through partners) for 24/7 operations.



Hosted and Hybrid




Self Hosted
