ARE YOU THINKING ABOUT
AI for SRE?
When developers are shipping faster, piling on more people and more dashboards creates more silos, more delays and more MTTR.
The problem to solve is enabling any engineer to root cause any issue in any part of your stack. Impossible? No.
Results at Fortune 100 scale like 70% faster MTTR and 1/6th the number of engineers in incident war rooms while steadily reducing observability spend.

How is RunWhen different?
Our "thousands of tools" approach is unique in the industry. Each agentic AI SRE tool is a short operational script whose outputs are optimized for LLMs. Diagnostics, validation, optimization, remediation...

Thousands of agentic AI SRE tools
in minutes
Give them credentials and our installers import thousands of agentic AI SRE tools for whatever they can find. Start with our tools then add your own. You have control.




Getting started with RunWhen

FIRST DAY: Thousands Of Default Tools
Install your first few thousands (read-only, safe) tools in minutes. The default AI SRE "Assistant" will use them.
Start asking questions immediately and see how it answers with the tools it has. Out of the box, it should have a pretty good feel for your infrastructure, common OSS components and stacktraces in your logs.
Get started with a kubeconfig and/or cloud credentials to cover a wide range of cloud infrastructure and application troubleshooting. No other integration needed.

FIRST WEEK: AI Learning Period
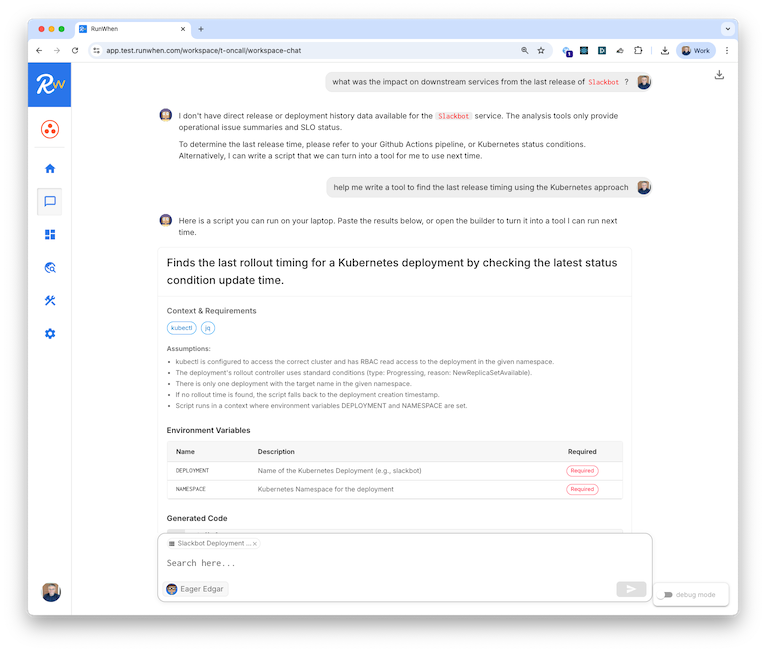
Either integrate with your existing alerts ("why is this firing?") or let RunWhen Assistants run continuously in the background.
They read the output of their tools and commit insights about your environment into their long term memory. The continue to get smarter about the tools they need to answer your question.
After about a week with the default Tasks, they should be ready to roll out to the team across dev/test environments.

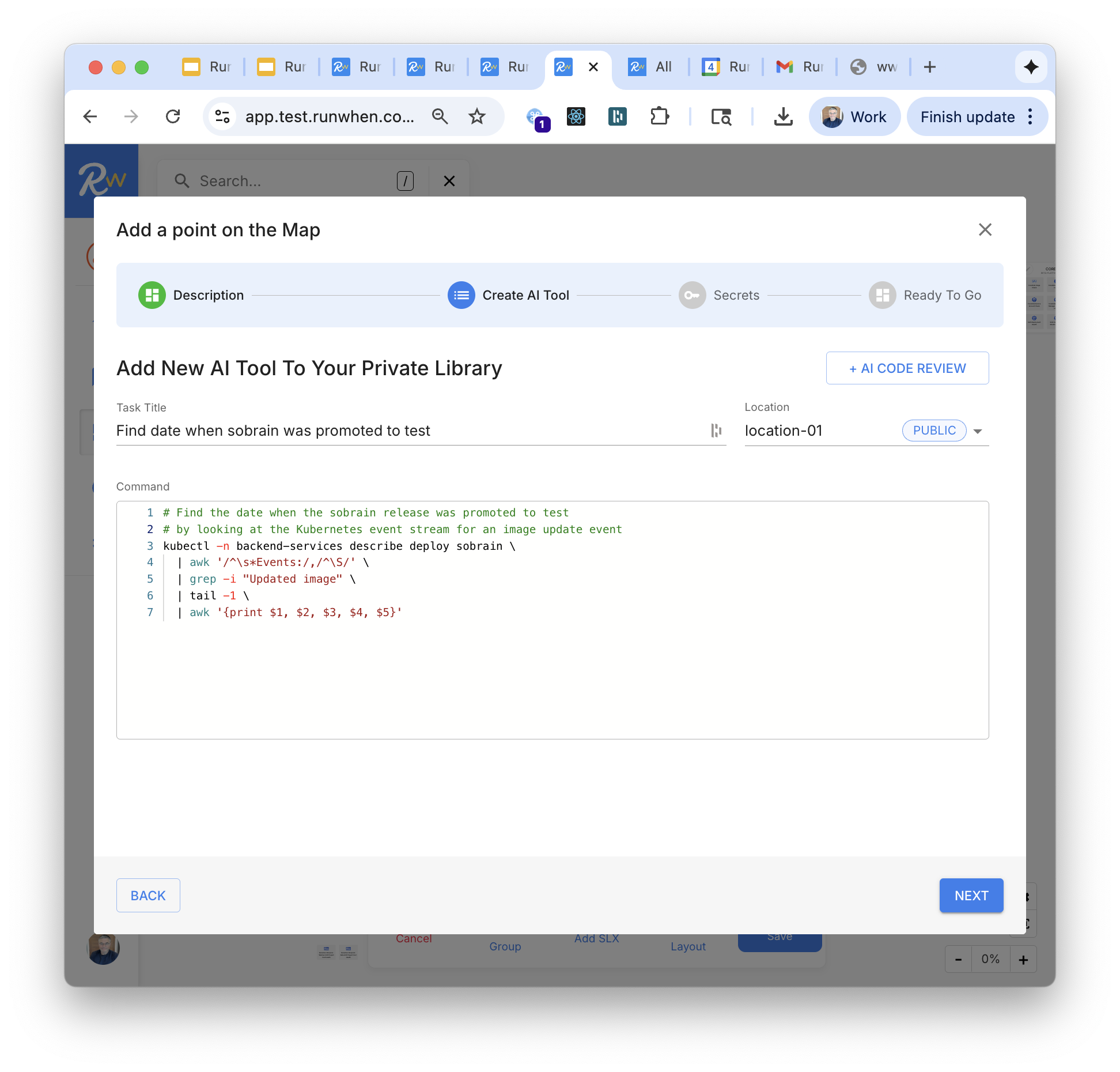
FIRST MONTH: "30 New Tools In 30 Days"
RunWhen or our partners' deploy forward-deployed engineers work with your team to build "30 tools in 30 days" to answer questions that unblock developers and reduce MTTR during incidents.
This integrates your AI SRE Assistant more deeply with your application's APIs, data and workflows. Typical tools query application APIs, query databases, automate common/safe remediation steps in non-prod environments.
After 30 days, your AI SRE Assistants should be demonstrating quantifiable reductions in MTTR in the environments where it has been deployed.

PRODUCTION: Thumbs Up?
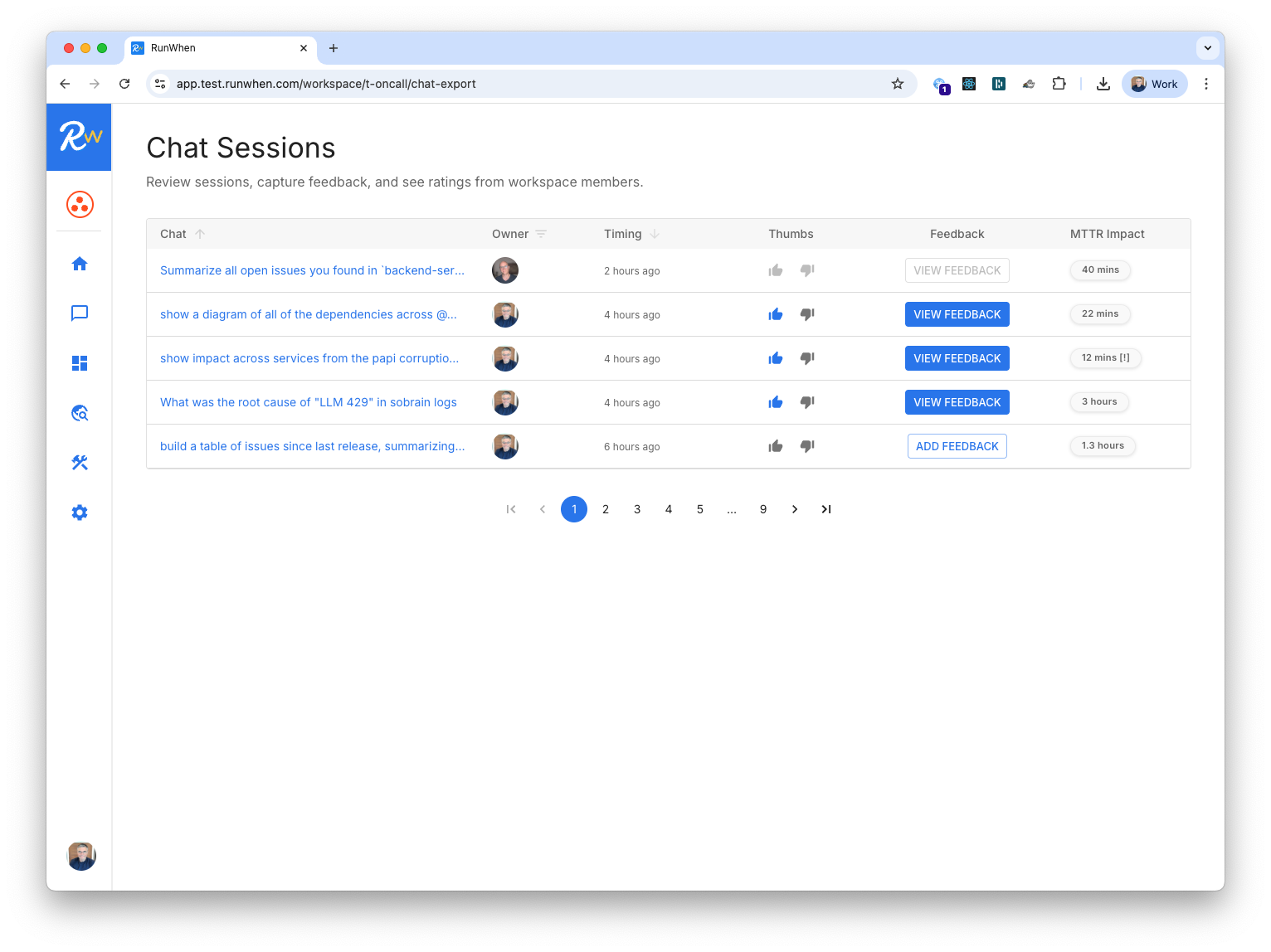
Each time an an engineer chats with an AI SRE Assistant, they get the chance to give a "thumbs up" if the session materially reduced MTTR or a "thumbs down" so the team can see where new tools are needed.
This results in i) a highly quantifiable business case, ii) a data-driven go/no decision about rolling this out to production, and iii) a high precision feedback loop when additional tools are needed to extend the system's capabilities.
Most teams are production-ready for incident response at the 30 day mark, and self-sufficient for building new tools if needed. Subsequent "30 tool in 30 day" sprints are available as professional services projects.


Can my team deploy RunWhen?
We work in the strictest financial services, health care and government environments in the industry
Need help with a business case?
Our team can help you build a business case for production environments, non-production environments, or both.
We typically do this after a 30 day PoV so we can use real production data in your environment.
Developer Productivity

“Developers ask us 10 questions per day. Each one implies they were blocked for about an hour. If they ask RunWhen AI Assistants, we get back 10 developer hours per day.”
Reliability vs Cloud Cost Trade-Offs

“RunWhen SLOs say this service is healthy 99.99% of the time. What if we drop to a 98% target and scale replica counts down by half?”
Scale Faster Than Headcount
.png)
“We have multiple cloud environments scaling up… I need either one more person per cloud environment or one person with ten RunWhen AI Assistants to cover both.”
Developer Self-Service

“Developers ask us 10 questions per day. Each one implies they were blocked for about an hour. If they ask RunWhen AI Assistants, we get back 10 developer hours per day.”
Reduce Downtime

“RunWhen can do a minor incident RCA in 2 minutes that typically takes about an hour. Assuming one minor incident per month…”
Reduce Observability Spend

“We can gradually cut back our observability bills in non-prod environments as teams get used to asking RunWhen AI Assistants questions instead of using dashboards.”
Reliability Program Value
.png)
“In between incidents, we followed the RunWhen Reliability To-Do list on our tier-1 services. Our top SLOs went from 96% to 98%, on track for 99% before year end...”
How are other teams using AI?

24/7 developer self service
This team is reducing developer escalations by 62%, giving dev teams their own specialized Engineering Assistants to troubleshoot CI/CD and infrastructure issues in shared environments.

Bring on-call back in-house
This team is reducing MTTR and saving cost, replacing an under-performing outsourced on-call service. They are giving Engineering Assistants to their expert SREs that respond to alerts by drafting tickets.
A (paid) community?
Interested in turning your hard-earned production experience into AI-ready automation? Expert authors in our community receive royalties and bounties when RunWhen customers use their automation. Note - expect rigorous human and AI code reviews and continuous testing requirements to join the program.




.svg)




Reduce observability costs? Let us show you how.
Unlike AI SRE tools built exclusively on observability data, our system leverages automation that pulls LLM-ready insights directly from your environment.
This means less observability spend rather than more, and less token spend processing data that was not built with LLMs in mind.
