streamline ENGINEERING
100x faster with Agentic AI
Build specialized SRE, Platform And DevOps Agents leveraging our massive library of AI-native automation. They respond to alerts and chats, draft tickets and more.












Thousands of tools configured for your environment in minutes
Sync your K8s / cloud accounts to auto-configure thousands of AI tools relevant for your stack. Our libraries cover cloud infrastructure, platform services, OSS, observability tools and more.




The RunWhen platform

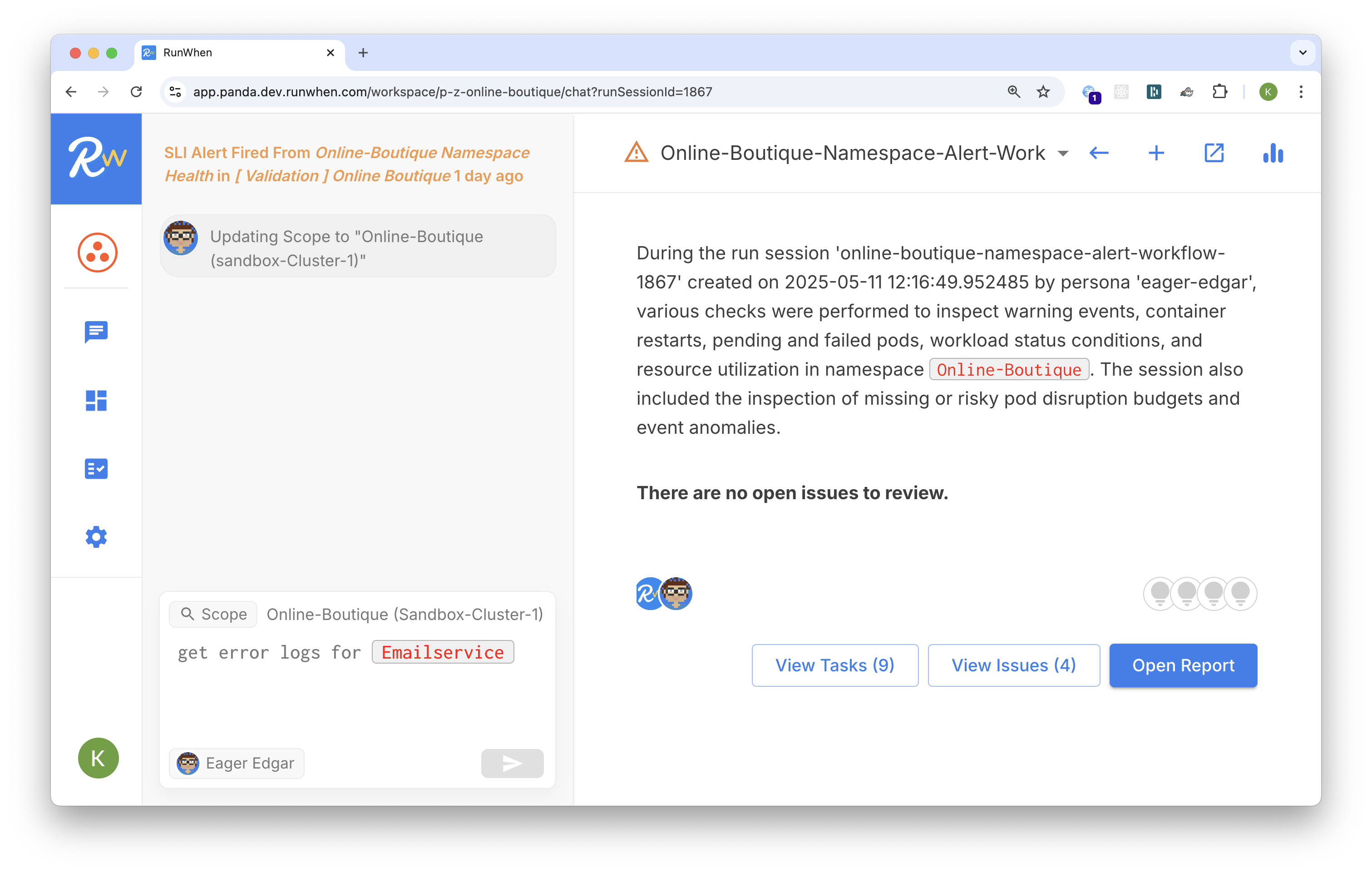
From Alerts To Tickets At 1/100th The Cost
Deploy an AI Engineering Assistant to handle alerts. It turns each alert into a search for the best (safe) automation to run, summarizing the results into engineering-ready tickets.
Let it automate remediation in non-prod environments, and set it to human-in-the-loop mode for production.
Industry benchmarks today show this process costs $500-700/ticket, but with RunWhen you can expect $5-7.
Self-Service Troubleshooting For Developers and On-Call teams In Slack
Deploy an AI Engineering Assistant to listen for questions in pre-production and production slack help channels. It turns each question into a search for the best (safe) automation, running this automation on the users' behalf.
It is instant self-service for your developers and L1 on-call staff, with guard rails attached and no training required.
>70% of dev teams building on Kubernetes report they get blocked on platform/infra issues at least once a month because they don't have tools like this.
.svg)
Like Cursor.ai For SREs
Any engineer can just type what is on their mind, and an Engineering Assistants will suggest (and run) automation, find relevant previous tickets or re-draft a ticket based on new information surfaced by the automations' results.
Check which services are impacted, fetch errors from logs, correlated this back to observability data and more while the Assistant is handling the write-up in parallel.
It is like vibe coding, but for troubleshooting complex environments.

Build Your AI Team
Each Engineering Assistant has its own scope, its own credentials and its own personality. Make some of them narrow for a small set of tasks, and others that cover entire environments. Make some read-only and others read-write.
The RunWhen platform is intended to build not one Engineering Assistant, but an entire team of Assistants that scales to the complexity of your organization.
By giving Assistants to your dev teams, your on-call teams and others, for the first time you actually can be everywhere at once.

Streamline the 70% of engineering time spent outside of code

24/7 developer self service
This team is reducing developer escalations by 62%, giving dev teams their own specialized Engineering Assistants to troubleshoot CI/CD and infrastructure issues in shared environments.

Bring on-call back in-house
This team is reducing MTTR and saving cost, replacing an under-performing outsourced on-call service. They are giving Engineering Assistants to their expert SREs that respond to alerts by drafting tickets.
Traditional automation vs RunWhen


RunWhen’s AI Engineering Assistants find automation and create variable workflows. Adding AI-native automation to your stack is 100x faster than traditional automation initiatives.
WitBh traditional tools, automating repetitive ops work typically takes more time than it saves. This automation is then fragile and flooded with dependencies that break the entire workflow.
With Runwhen we transform your workflow

Automation can cut observability costs
Some of our most popular automation libraries copy logs directly from pods and VMs into Jira/Github tickets. Connecting this to VSCode, alerts and CI/CD webhooks removes the need to ingest and store 90%+ of non-prod logs.


Where to next?
The default Assistants that come out of the box are designed for Platform/SRE teams to give to developers for Kubernetes troubleshooting. However, it doesn't stop there...
Connect To Slack

Connect AI Assistants to Slack so anyone on the team can ask an Engineering Assistant for root cause or remediation help 24/7.
Add No-Code Steps

Add No-Code "Generics," simple application troubleshooting steps like checking a REST API, a SQL query or pre-canned log search. These require only a few lines of configuration to be Engineering Assistant-ready
Connect To CI/CD Pipelines
.png)
Connect to CI/CD pipelines and use Engineering Assistants to run thousands of troubleshooting tasks. They report back on issues found and severity, creating metrics for operational readiness.
Distribute The VSCode Plugin

When you are ready to give your developers the gift of self-serve troubleshooting, consider distributing our VSCode plugin.
Manage to SLOs
.png)
RunWhen's defaults include automation to generate fine-grained SLIs, SLOs and Monthly Error Budgets based on community benchmarks that are useful in dev, staging and production.
A (paid) community?
Expert authors in our community receive royalties and bounties when RunWhen customers use their automation. The community's efforts span infrastructure, cloud services and platform components alongside popular OSS components, programming languages and frameworks.




.svg)




Running a lean team means you need the best engineers you can find...
Do you really want your top engineers spending time on work that someone in industry already automated?
